Abstract
Neural vocoders can synthesize high-quality speech waveforms from acoustic features, but they cannot control by acoustic parameters, such as $F_0$ and formant frequencies. Although analysis-synthesis based on signal processing can be controlled using acoustic parameters, its speech quality is inferior to that of neural vocoders.
This paper proposes End-to-End Neural Formant Synthesis for generating high-quality speech waveforms with controllable acoustic parameters from low-dimensional representations. We compared three models with different structures, and investigated their synthesis quality and controllability. Experimental results showed that the proposed method performed as well as or better than conventional methods in terms of speech quality and controllability.
Proposed Methods
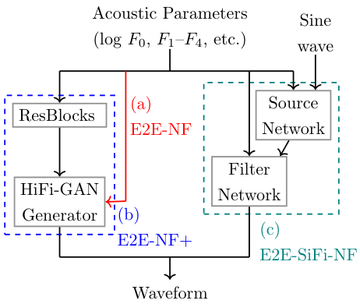
Architecture of proposed models.
(a) E2E-NF, (b) E2E-NF+, and (c) E2E-SiFi-NF.
Experimental Results
The JVS corpus1, which comprised recordings of 100 Japanese speakers (male and female) at 24 kHz, served as the dataset. The evaluation was conducted using four speakers: two male (JVS001 and JVS003) and two female (JVS002 and JVS004).
We compared our method with both conventional methods, Neural Formant (NF)2 and HiFi-GAN3 which synthesizes speech waveforms using acoustic features. E2E-NF, E2E-NF+, and E2E-SiFi-NF were trained for 400 K steps each. HiFi-GAN v1 trained for 400K steps as neural vocoder of NF, employing an 80-dimensional mel-spectrogram. NF training consisted of 99 K steps, which is consistent with previous work.
Analysis Synthesis
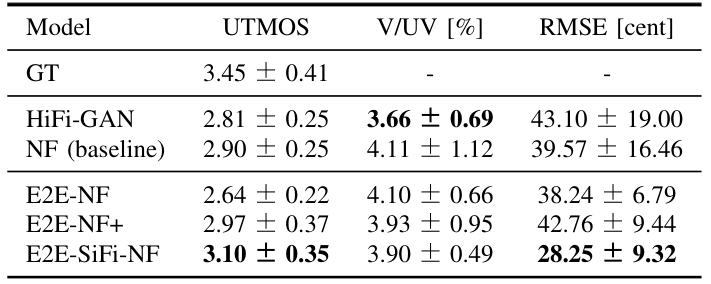
Results of objective and subjective evaluations for analysis synthesis.
Audio Samples
| Speaker |
|---|
Manipulated Synthesis
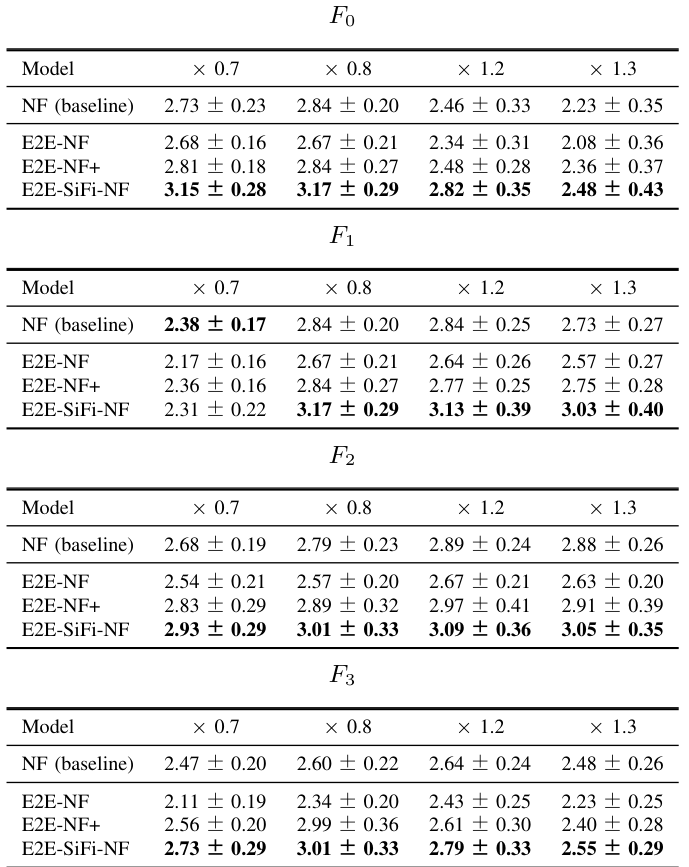
UTMOS4 results of acoustic parameter manipulation.
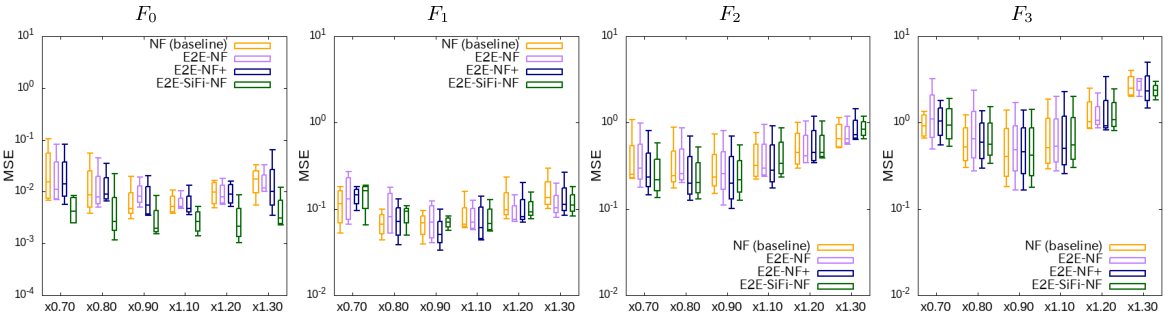
Log-scale plot of MSE for manipulated acoustic parameters.
Audio Samples
| Speaker | Acoustic parameter |
|---|
References
S. Takamichi, K. Mitsui, Y. Saito, T. Koriyama, N. Tanji, and H. Saruwatari, “JVS corpus: free japanese multi-speaker voice corpus,” arXiv preprint, 1908.06248, 2019. ↩︎
P. P. Zarazaga, Z. Malisz, G. E. Henter, and L. Juvela, “Speaker- independent neural formant synthesis,” in Proc. Interspeech, 2023, pp. 5556–5560. ↩︎
J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,” in Proc. NeurIPS, vol. 33, 2020, pp. 17 022–17 033. ↩︎
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: Utokyo-sarulab system for voicemos chal-lenge 2022,” arXiv preprint, 2204.02152, 2022. ↩︎